Reddit Discussion of TV - Natural Language Processing
Reddit Discussion of TV episodes
Max Garber
Project Description
Backstory:Using data we scrape from the web, what can we learn about our data via unsupervised learning techniques? Extend your analysis by combining unsupervised and supervised learning methods, or by developing a recommender system, etc.
Data:type: text data
acquisition: api's, scraping, etc.
storage: mongodb
Skills & Tools:flask
mongodb
nlp
unsupervised learning
dimensionality reduction
topic modeling
recommender systems
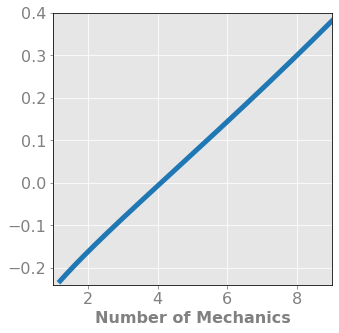
Analysis:unsupervised learning (clustering and/or dimensionality reduction) is required, other types of modeling (listed above) are encouraged.
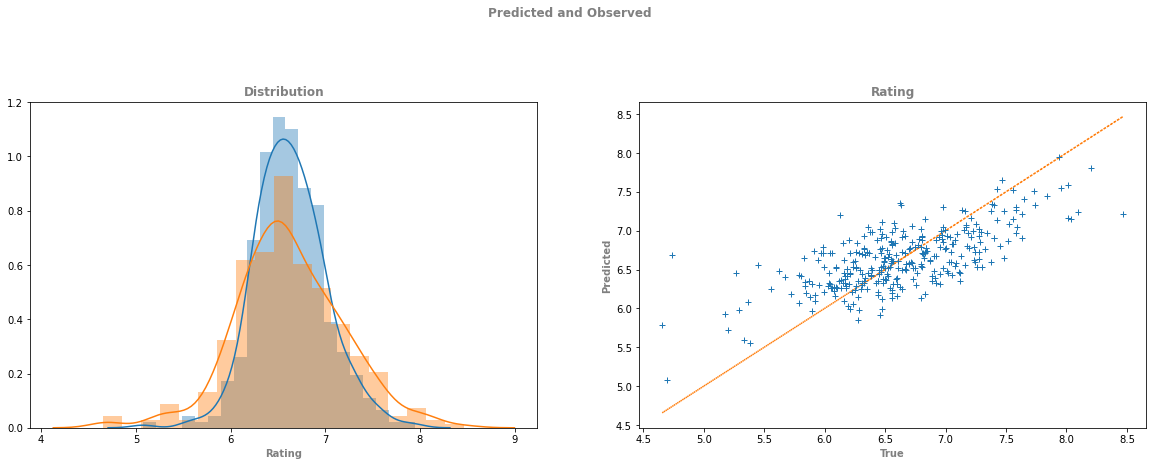
I looked at the discussion on a tv shows subreddit following the premiere date of each episode of the show. I was looking to determine if there was a relationship between the discussion of an episode and the rating of that episode.
The Data
Using the pushshift.io 3rd party API for reddit I got the top (by score) 100 Reddit posts between 1 and 3 days after an episode premiered from the shows subreddit
I also got Information about each episode from The Movie Database and scraped rating from Rotten Tomatoes>
Text Processing
First the title and text of each post was combined. Then the text was cleaned, tokenized, stemmed, stopwords removed and tagged with Parts of Speech. Finally the corpus was converted to a matrix with a Count Vectorizer and TF-IDF.

Topic Modeling : Westworld
I decided to use Westworld as my test case since season 3 had recently ended and it was fresh in my memory.
I used Latent Semantic Analysis to extract topics from the data. The topics corresponded to different story lines of the show.

Sentiment Analysis : Westworld:
I then did Sentiment Analysis on the data using VADER. There does appear to be loose correlation between the sentiment of the discussion of each episode and the rating of the episode thou it was not a strong as I hoped.